LeetsGoAgain
二叉树
- 二叉树
- 二叉树理论基础
- 二叉树的递归遍历
- 二叉树的迭代遍历(重要)
- 二叉树的统一迭代法(较难理解)
- 二叉树的层序遍历(重要)
- 翻转二叉树
- 对称二叉树
- 二叉树的最大深度
- 二叉树的最小深度
- 完全二叉树的节点个数
- 平衡二叉树
- 二叉树的所有路径(重要:回溯基本题)
- 左叶子之和
- 找树左下角的值
- 路径总和
- 从中序与后序遍历序列构造二叉树(重要题型)
- 最大二叉树
- 合并二叉树
- 二叉搜索树中的搜索
- 验证二叉搜索树
- 二叉搜索树的最小绝对差
- 二叉搜索树中的众数
- 二叉树的最近公共祖先(需要复习)
- 二叉搜索树的最近公共祖先
- 二叉搜索树中的插入操作
- 删除二叉搜索树中的节点(难)
- 修剪二叉树(需要复习)
- 将有序数组转换为二叉搜索树(可以联想到:AVL的旋转)
- 把二叉搜索树转换为累加树(反中序遍历)
二叉树理论基础
二叉树的一些用语:
此部分内容我是熟悉的,不过在这里再次复习。
- 满二叉树: 如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。
- 深度为k,有
2^k-1个节点的二叉树。
- 深度为k,有
- 完全二叉树: 在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。
- 若最底层为第 h 层(h从1开始),则该层包含
1~2^(h-1)个节点。
- 若最底层为第 h 层(h从1开始),则该层包含
- 二叉搜索树: 二叉搜索树是一个有序树。
- 平衡二叉搜索树: 又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
二叉树的存储:
注意:二叉树可以链式存储,也可以顺序存储。
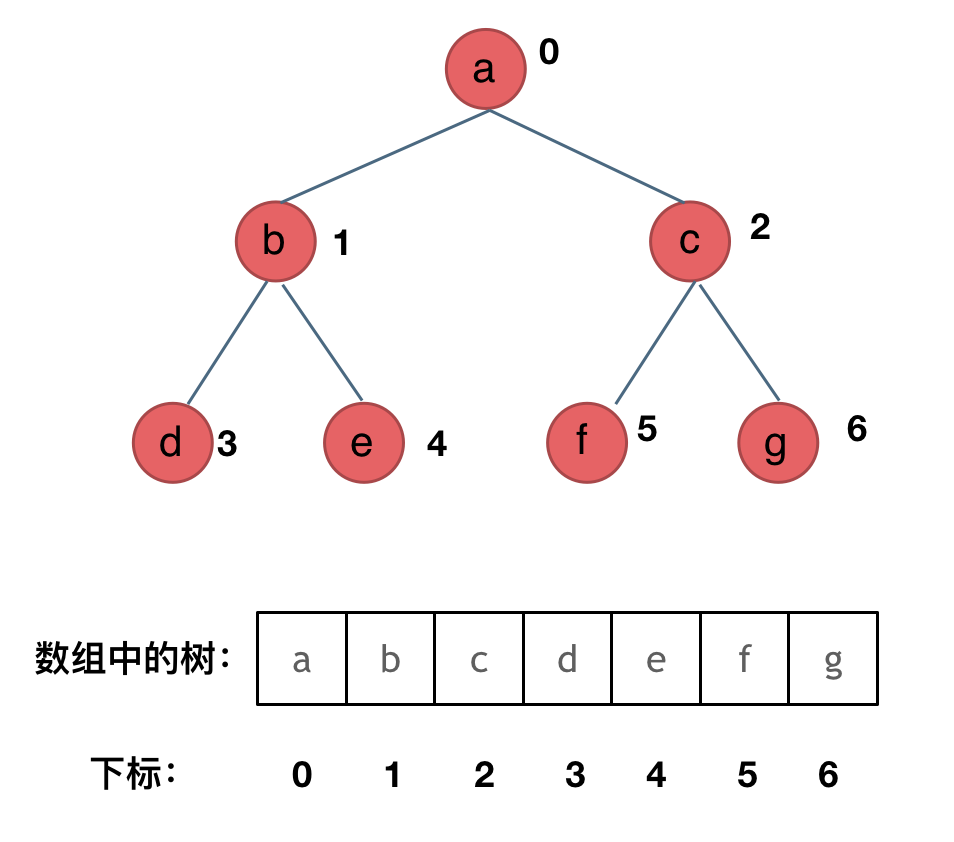
如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。
这个结论非常的重要,需要记住。
二叉树的遍历:
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层次遍历(迭代法)
二叉树的链式存储定义:
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
二叉树的递归遍历
其实就是前中后序。
递归一定要注意:
- 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数,并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
- 确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
- 确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
144. 二叉树的前序遍历
45. 二叉树的后序遍历
94. 二叉树的中序遍历
前序:
class Solution {
private:
std::vector<int> res;
void dfs(TreeNode* node) {
if(!node) return;
res.push_back(node->val);
if(node->left) dfs(node->left);
if(node->right) dfs(node->right);
}
public:
vector<int> preorderTraversal(TreeNode* root) {
dfs(root);
return res;
}
};
后序:
class Solution {
private:
std::vector<int> res;
void dfs(TreeNode* node) {
if(!node) return;
if(node->left) dfs(node->left);
if(node->right) dfs(node->right);
res.push_back(node->val);
}
public:
vector<int> postorderTraversal(TreeNode* root) {
dfs(root);
return res;
}
};
中序:
class Solution {
private:
std::vector<int> res;
void dfs(TreeNode* node) {
if(!node) return;
if(node->left) dfs(node->left);
res.push_back(node->val);
if(node->right) dfs(node->right);
}
public:
vector<int> inorderTraversal(TreeNode* root) {
dfs(root);
return res;
}
};
二叉树的迭代遍历(重要)
前序遍历
一句话说清楚:先把root放到stack里,root出栈的时候,把孩子带进(先带右孩子啊,再带左孩子)
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
if(root == nullptr) return {};
std::stack<TreeNode*> st;
std::vector<int> res;
st.push(root);
while(!st.empty()) {
TreeNode* node = st.top(); // 当前要访问的节点
res.push_back(node->val);
st.pop(); // 弹出并访问root
if(node->right) st.push(node->right); // 把右孩子带进去
if(node->left) st.push(node->left); // 把左孩子带进去
}
return res;
}
};
但接下来,再用迭代法写中序遍历的时候,会发现套路又不一样了,目前的前序遍历的逻辑无法直接应用到中序遍历上。
中序遍历
中序遍历会有点难,一定要学会!这个是很重要的!因为后续面搜索树写迭代器,也是这个中序顺序!!!
分析一下为什么刚刚写的前序遍历的代码,不能和中序遍历通用呢,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
那么再看看中序遍历,中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
if(root == nullptr) return {};
std::stack<TreeNode*> st;
std::vector<int> res;
TreeNode* cur = root;
while(cur || !st.empty()) {
// 先找以cur为开始,最左边的后代节点
if(cur) {
st.push(cur); // 把访问到的节点放进栈
cur = cur->left;
}
else {
// 此时cur为nullptr
cur = st.top(); // 则访问到这个cur之前的上一个非空(同时也在栈里),我们就可以去访问这个节点了
st.pop();
res.push_back(cur->val);
cur = cur->right; // 如果有右,则会以 cur->right 开始的最左子孙节点;如果没有右,则继续访问栈里的
}
}
return res;
}
};
后序遍历
再来看后序遍历,先序遍历是中左右,后序遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了。

代码如下:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
if(root == nullptr) return {};
std::stack<TreeNode*> st;
std::vector<int> res;
st.push(root);
while(!st.empty()) {
auto cur = st.top();
st.pop();
res.push_back(cur->val);
if(cur->left) st.push(cur->left);
if(cur->right) st.push(cur->right);
}
std::reverse(res.begin(), res.end());
return res;
}
};
二叉树的统一迭代法(较难理解)
上面提到说使用栈的话,无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。
那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢?
-
方法一:就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记。 这种方法可以叫做空指针标记法。
-
方法二:加一个 boolean 值跟随每个节点,false (默认值) 表示需要为该节点和它的左右儿子安排在栈中的位次,true 表示该节点的位次之前已经安排过了,可以收割节点了。 这种方法可以叫做 boolean 标记法,样例代码见下文C++ 和 Python 的 boolean 标记法。 这种方法更容易理解,在面试中更容易写出来。
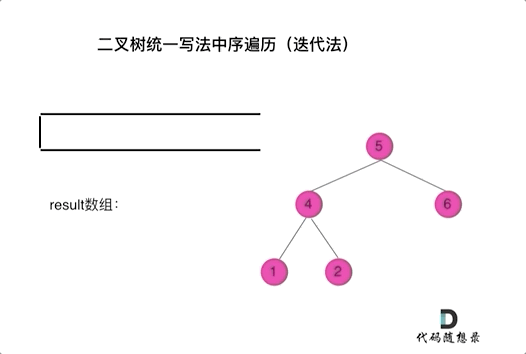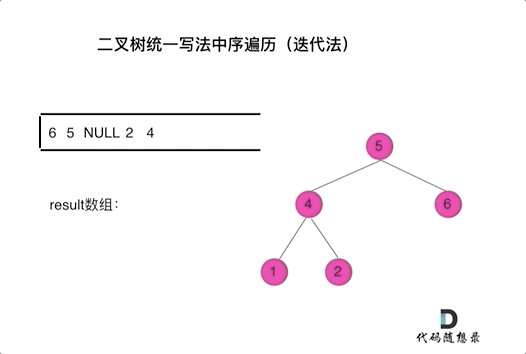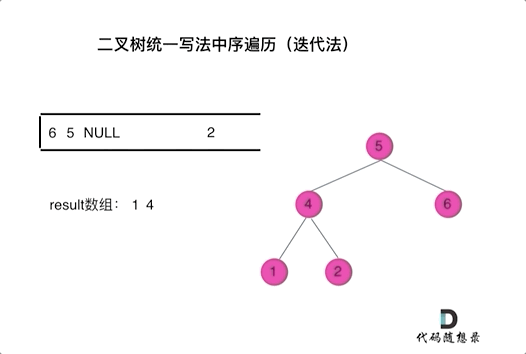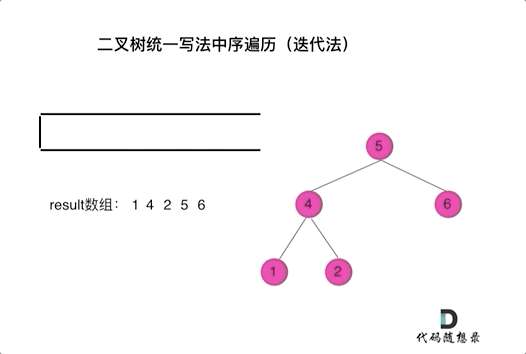
其实思路和之前是一样的。
Note by Yufc: 因为从上往下访问,必须要访问到root才能访问到children,但是,访问root的时候,不能加到res里面去,所以要先记录:这个root已经被处理,但是还没有加入到结果中。
总之,一个节点要被加入到res中,那么他前面一定要有一个null;那么这个节点如何才能拥有这个null呢?把右左孩子带进来,你就可以拥有这个null了!
这样,就不用按照上面那种找最左边的子孙节点了。
迭代法中序遍历尝试谢谢:
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
if(!root) return {};
std::stack<TreeNode*> st;
std::vector<int> res;
st.push(root); // 先不要放到结果里
while(!st.empty()) {
auto node = st.top();
if(node) {
// 不是空指针 要将这个节点弹出来 避免重复操作
st.pop();
if(node->right) st.push(node->right); // 右
st.push(node); // 重新插入这个节点
st.push(nullptr); // 表示这个中间节点已经被访问了
if(node->left) st.push(node->left); // 左
} else {
// 遇到空指针,说明null前面的那个node的左和右已经处理好了
st.pop();
node = st.top();
st.pop();
res.push_back(node->val);
}
}
return res;
}
};
反正:中左右分别就是这几行,因为是栈,所以反过来就行。中序遍历需要左中右,插入就是右左中。后序和前序是同一个道理。
if(node->right) st.push(node->right); // 右
st.push(node); // 中
st.push(nullptr);
if(node->left) st.push(node->left); // 左
前序:
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
if(!root) return {};
std::stack<TreeNode*> st;
std::vector<int> res;
st.push(root);
while(!st.empty()) {
auto node = st.top();
if(node) {
// 这个节点前没有null,因此需要把孩子弄进去,才能给他发放一个null
st.pop(); // 先暂时弹出这个节点
// 前序需要 中 左 右
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
st.push(node);
st.push(nullptr); // 发放 null
} else {
// node为null
st.pop();
node = st.top();
st.pop();
res.push_back(node->val);
}
}
return res;
}
};
后序:
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
if(!root) return {};
std::stack<TreeNode*> st;
std::vector<int> res;
st.push(root);
while(!st.empty()) {
auto node = st.top();
if(node) {
// 这个节点前没有null,因此需要把孩子弄进去,才能给他发放一个null
st.pop(); // 先暂时弹出这个节点
// 后需要 左 右 中
st.push(node);
st.push(nullptr); // 发放 null
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
} else {
// node为null
st.pop();
node = st.top();
st.pop();
res.push_back(node->val);
}
}
return res;
}
};
boolean 标记法其实是一样的,前面这种是:一个节点想要放入res,必须前面有个null。这里换成,一个节点想要放入res,必须是true,而不是false。
stack里面放个pair就行。
顺利通过。
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
if(!root) return {};
std::stack<std::pair<TreeNode*, bool>> st;
std::vector<int> res;
st.push({root, false});
while(!st.empty()) {
auto node_pair = st.top();
TreeNode* node = node_pair.first;
bool is_valid = node_pair.second;
if(!is_valid) {
st.pop(); // 先弹出此节点
// 中序需要 左 中 右
if(node->right) st.push({node->right,false});
st.push({node, true}); // 标记为true
if(node->left) st.push({node->left,false});
} else {
node_pair = st.top();
st.pop();
res.push_back(node_pair.first->val);
}
}
return res;
}
};
二叉树的层序遍历(重要)
层序相关题目:
- 102. 二叉树的层序遍历
- 107. 二叉树的层次遍历II
- 199. 二叉树的右视图
- 637. 二叉树的层平均值
- 429. N叉树的层序遍历
- 515. 在每个树行中找最大值
- 116. 填充每个节点的下一个右侧节点指针
- 117. 填充每个节点的下一个右侧节点指针II
- 104. 二叉树的最大深度
- 111. 二叉树的最小深度
二叉树的层序遍历
https://leetcode.cn/problems/binary-tree-level-order-traversal/
用队列先进先出就行,和stack用来深度遍历一样,出队列的时候把两个孩子带进来就行了。
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
if(!root) return {};
std::vector<std::vector<int>> res;
std::queue<TreeNode*> q;
q.push(root);
while(!q.empty()) {
int sz = q.size();
std::vector<int> vec;
for(int i = 0; i < sz; ++i) {
TreeNode* node = q.front();
q.pop();
vec.push_back(node->val);
if(node->left) q.push(node->left); // 把孩子带进去
if(node->right) q.push(node->right); // 把孩子带进去
}
res.push_back(vec);
}
return res;
}
};
这一份就是层序遍历的核心代码,很重要!
二叉树的层次遍历 II
给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
https://leetcode.cn/problems/binary-tree-level-order-traversal-ii/description/
上面那题的基础上反转一下结果的数组就行了。
class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
if(!root) return {};
std::vector<std::vector<int>> res;
std::queue<TreeNode*> q;
q.push(root);
while(!q.empty()) {
int sz = q.size();
std::vector<int> vec;
for(int i = 0; i < sz; ++i) {
TreeNode* node = q.front();
q.pop();
vec.push_back(node->val);
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
res.push_back(vec);
}
std::reverse(res.begin(), res.end());
return res;
}
};
二叉树的右视图
https://leetcode.cn/problems/binary-tree-right-side-view/description/
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
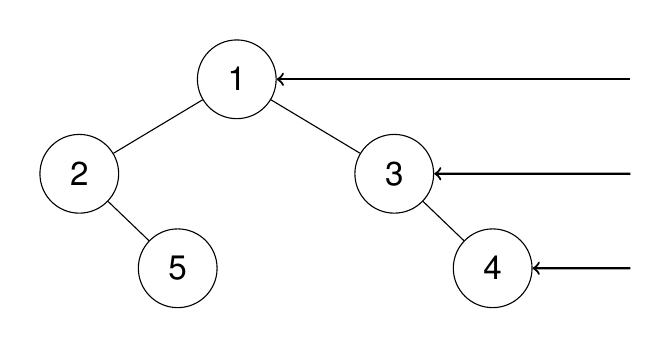
输入:root = [1,2,3,null,5,null,4]
输出:[1,3,4]
其实很好理解,层序遍历的时候,遍历到本层最后一个节点,才加入到结果中。
直接写代码:
class Solution {
public:
vector<int> rightSideView(TreeNode* root) {
if(!root) return {};
std::queue<TreeNode*> q;
std::vector<int> res;
q.push(root);
while(!q.empty()){
int sz = q.size();
for(int i = 0; i < sz; ++i) {
auto node = q.front();
q.pop();
// 如果是本层最后一个,才加入到结果中
if(i == sz - 1)
res.push_back(node->val);
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
}
return res;
}
};
直接通过,很顺利。
二叉树的层平均值
https://leetcode.cn/problems/average-of-levels-in-binary-tree/description/
计算每一层的平均值,很简单,求和除一下就行了。
class Solution {
public:
vector<double> averageOfLevels(TreeNode* root) {
if(!root) return {};
std::queue<TreeNode*> q;
std::vector<double> res;
q.push(root);
while(!q.empty()) {
int sz = q.size();
double sum = 0;
for(int i = 0; i < sz; ++i) {
auto node = q.front();
q.pop();
sum += node->val;
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
res.push_back(sum / sz);
}
return res;
}
};
N叉树的层序遍历
https://leetcode.cn/problems/n-ary-tree-level-order-traversal/description/
同理,把每一个孩子都带进去就行了,都是一样的。
class Solution {
public:
vector<vector<int>> levelOrder(Node* root) {
if(!root) return {};
std::queue<Node*> q;
std::vector<std::vector<int>> res;
q.push(root);
while(!q.empty()) {
int sz = q.size();
std::vector<int> layer;
for(int i = 0; i < sz; ++i) {
Node* node = q.front();
q.pop();
layer.push_back(node->val);
for(const auto& e : node->children) // 把每一个孩子都带进去
if(e)
q.push(e);
}
res.push_back(layer);
}
return res;
}
};
顺利通过。
在每个树行中找最大值
https://leetcode.cn/problems/find-largest-value-in-each-tree-row/description/
给定一棵二叉树的根节点 root ,请找出该二叉树中每一层的最大值。
简单,直接写代码。
class Solution {
public:
vector<int> largestValues(TreeNode* root) {
if(!root) return {};
std::queue<TreeNode*> q;
std::vector<int> res;
q.push(root);
while(!q.empty()) {
int sz = q.size();
int max = INT_MIN;
for(int i = 0; i < sz; ++i) {
TreeNode* node = q.front();
q.pop();
if(node->val > max) // 计算最大值
max = node->val;
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
res.push_back(max);
}
return res;
}
};
填充每个节点的下一个右侧节点指针
给一个完美二叉树

填充这些指针。很简单,获取到每一层就行了。
class Solution {
public:
Node* connect(Node* root) {
if(!root) return nullptr;
std::queue<Node*> q;
q.push(root);
while(!q.empty()) {
int sz = q.size();
Node* cur = nullptr; // 用双指针记录前面的节点就行了
Node* pre = nullptr; // 这里是链表题目打下的基础
for(int i = 0; i < sz; ++i) {
cur = q.front();
auto node = q.front();
q.pop();
if(i == 0) {
cur->next = nullptr;
} else {
pre->next = cur;
cur->next = nullptr;
}
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
pre = cur;
}
}
return root;
}
};
填充每个节点的下一个右侧节点指针II
https://leetcode.cn/problems/populating-next-right-pointers-in-each-node-ii/description/
和上一题代码没有任何区别。
二叉树的最大深度
https://leetcode.cn/problems/maximum-depth-of-binary-tree/description/
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
这题是可以递归的,但是这里先用层序遍历做下先。
class Solution {
public:
int maxDepth(TreeNode* root) {
if(!root) return 0;
size_t layer = 0;
std::queue<TreeNode*> q;
q.push(root);
while(!q.empty()) {
int sz = q.size();
for(int i = 0; i < sz; ++i) {
auto node = q.front();
q.pop();
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
layer++; // 记录层数即可
}
return layer;
}
};
二叉树的最小深度
https://leetcode.cn/problems/minimum-depth-of-binary-tree/description/
一层一层搞,如果左右孩子都为空,就返回记录的深度就行了。
class Solution {
public:
int minDepth(TreeNode* root) {
if(!root) return 0;
std::queue<TreeNode*> q;
q.push(root);
int depth = 0;
while(!q.empty()) {
int sz = q.size();
depth++; // 在这里就要++了,不能放到for结束,不然return的时候就没++到了
for(int i = 0; i < sz; ++i) {
auto node = q.front();
q.pop();
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
if(!node->left && !node->right) return depth;
}
}
assert(false);
return -1;
}
};
翻转二叉树
https://leetcode.cn/problems/invert-binary-tree/
思路:把每一个节点的左右孩子都交换一下,就能完成翻转。
用递归比较好。
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(!root) return nullptr;
std::swap(root->left, root->right);
invertTree(root->left);
invertTree(root->right);
return root;
}
};
当然,用栈也是一样的。
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(!root) return nullptr;
std::stack<TreeNode*> st;
st.push(root);
while(!st.empty()) {
TreeNode* node = st.top(); // 中
st.pop();
std::swap(node->left, node->right);
if(node->right) st.push(node->right); // 右
if(node->left) st.push(node->left); // 左
}
return root;
}
};
用队列也是一样的!反正只要能遍历每一个节点的方法,都可以用! 这里再复习一次层序遍历。
class Solution {
public:
TreeNode* invertTree(TreeNode* root) {
if(!root) return nullptr;
std::queue<TreeNode*> q;
q.push(root);
while(!q.empty()) {
int sz = q.size();
for(int i = 0; i < sz; ++i) {
auto node = q.front();
q.pop();
std::swap(node->left, node->right);
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
}
return root;
}
};
对称二叉树
常规方法
https://leetcode.cn/problems/symmetric-tree/description/
判断一个二叉树是不是对称的。
思路:递归遍历每一个节点,看看是不是左右对称即可。
class Solution {
private:
bool compare(TreeNode* left, TreeNode* right) {
if(!left && right) return false; // 设置返回条件
if(left && !right) return false; // 设置返回条件
if(!left && !right) return true; // 设置返回条件
if(left->val != right->val) return false; // 设置返回条件
return compare(left->left, right->right) && compare(left->right, right->left); // 继续递归
}
public:
bool isSymmetric(TreeNode* root) {
if(!root) return true;
return compare(root->left, root->right);
}
};
这题也是很好理解的,看看代码就行。
迭代方法
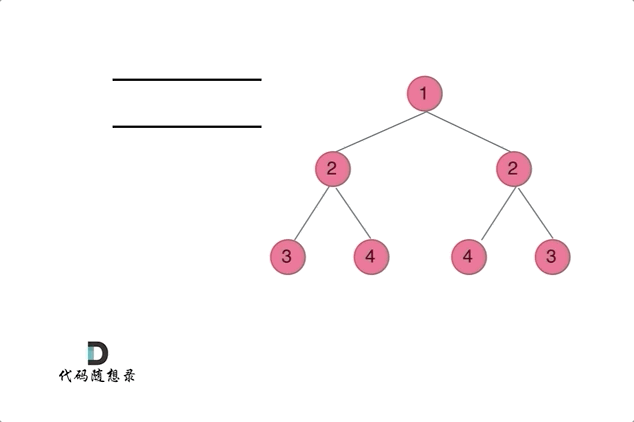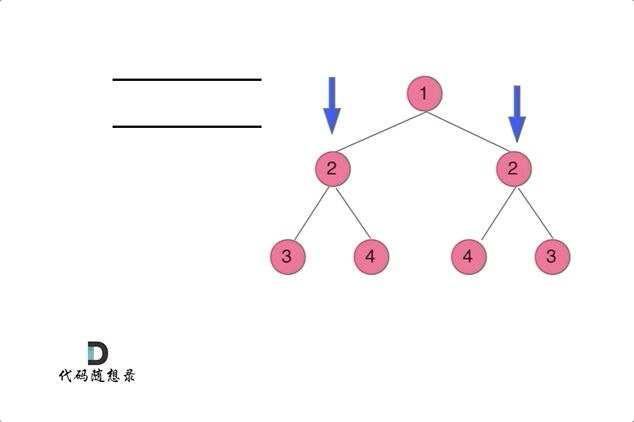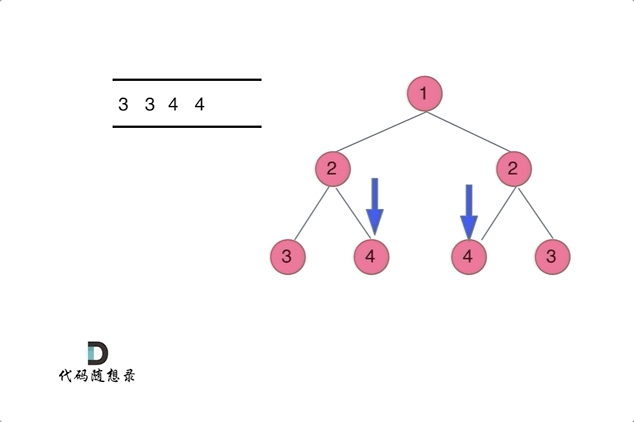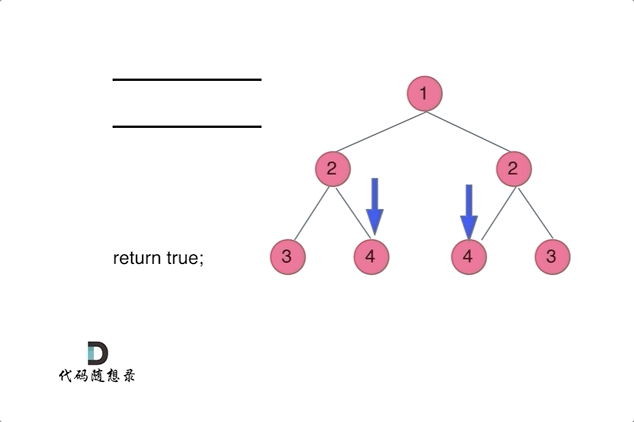
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if(!root) return true;
std::queue<TreeNode*> q;
q.push(root->left);
q.push(root->right);
while(!q.empty()) {
TreeNode* left_node = q.front(); q.pop();
TreeNode* right_node = q.front(); q.pop();
if(!left_node && right_node) return false; // 设置返回条件
if(left_node && !right_node) return false; // 设置返回条件
if(!left_node && !right_node ) continue; // 左右节点都为空
if(left_node->val != right_node->val) return false;
// 这里四个要注意顺序
q.push(left_node->left);
q.push(right_node->right);
q.push(left_node->right);
q.push(right_node->left);
}
return true;
}
};
相同的树
https://leetcode.cn/problems/same-tree/description/
class Solution {
private:
bool compare(TreeNode* node1, TreeNode* node2) {
if(!node1 && !node2) return true;
if((node1 && !node2) || (!node1 && node2)) return false;
if(node1->val != node2->val) return false;
return compare(node1->left, node2->left) && compare(node1->right, node2->right);
}
public:
bool isSameTree(TreeNode* p, TreeNode* q) {
return compare(p, q);
}
};
用一个 bool compare(TreeNode* node1, TreeNode* node2), 相同思路,直接解决。
另一棵树的子树
https://leetcode.cn/problems/subtree-of-another-tree/description/
class Solution {
private:
bool compare(TreeNode* node1, TreeNode* node2) {
if(!node1 && !node2) return true;
if((node1 && !node2) || (!node1 && node2)) return false;
if(node1->val != node2->val) return false;
return compare(node1->left, node2->left) && compare(node1->right, node2->right);
}
public:
bool isSubtree(TreeNode* root, TreeNode* subRoot) {
if(!root && !subRoot) return true;
if((root && !subRoot) || (!root && subRoot)) return false;
if(compare(root, subRoot)) return true; // note
return isSubtree(root->left, subRoot) || isSubtree(root->right, subRoot); // note
}
};
注意这两行:
if(compare(root, subRoot)) return true; // note
return isSubtree(root->left, subRoot) || isSubtree(root->right, subRoot); // note
如果两个树相同,就是true,如果不相同,要重新调用 isSubtree 而不是重新调用 compare,这里要注意。
把队列直接换成栈,其他不用动,也是可以通过的。思考一下就能想明白。
二叉树的最大深度
https://leetcode.cn/problems/maximum-depth-of-binary-tree/
class Solution {
public:
int maxDepth(TreeNode* root) {
if(root == nullptr) return 0;
return 1 + std::max(maxDepth(root->left), maxDepth(root->right));
}
};
N 叉树的最大深度
https://leetcode.cn/problems/maximum-depth-of-n-ary-tree/
class Solution {
public:
int maxDepth(Node* root) {
if(root == nullptr) return 0;
int _max = 0;
for(int i = 0; i < root->children.size(); ++i) {
int depth = maxDepth(root->children[i]);
if(depth > _max)
_max = depth;
}
return _max + 1;
}
};
思路和上面是一样的。
二叉树的最小深度
https://leetcode.cn/problems/minimum-depth-of-binary-tree/
class Solution {
public:
int minDepth(TreeNode* root) {
if(!root) return 0;
// 此处要注意,和求最大深度是有区别的。
// 要找叶子结点,如果 root->left == null,是不能直接返回depth=1的
if(root->left == nullptr && root->right) return 1 + minDepth(root->right);
if(root->right == nullptr && root->left) return 1 + minDepth(root->left);
return 1 + std::min(minDepth(root->left), minDepth(root->right));
}
};
NOTE: 要找叶子结点,如果 root->left == null,是不能直接返回depth=1的。
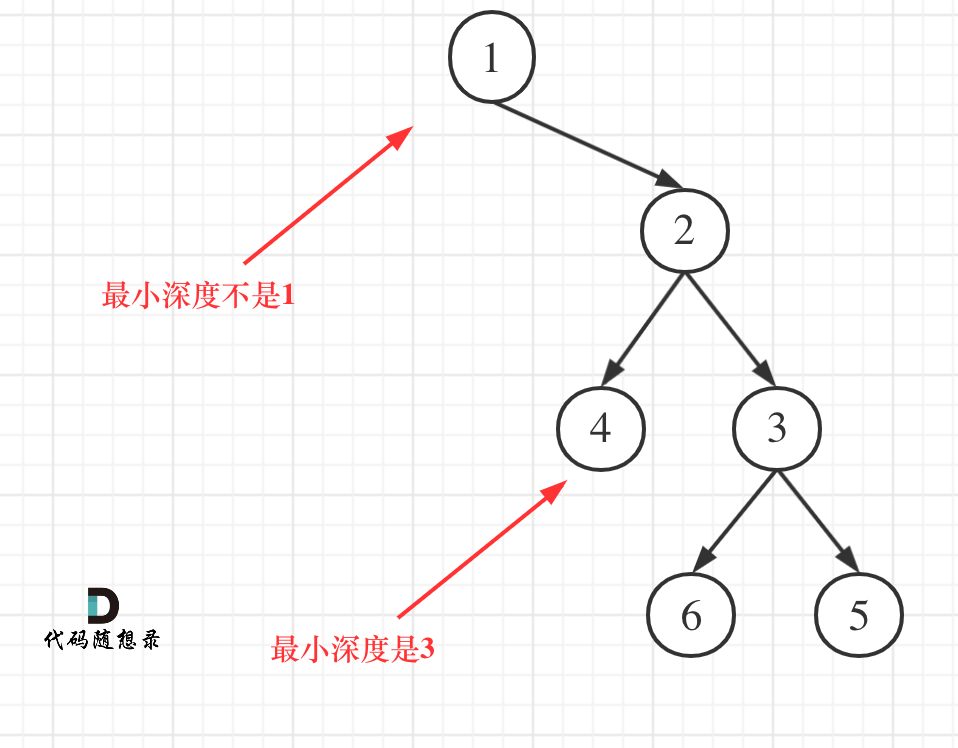
如图所示。
完全二叉树的节点个数
https://leetcode.cn/problems/count-complete-tree-nodes/description/
这题最无脑的方法肯定就是当普通二叉树来求节点个数即可。
class Solution {
public:
int countNodes(TreeNode* root) {
return root==NULL?0:countNodes(root->left)+countNodes(root->right)+1;
}
};
这里不赘述。
这里来学习一种,利用完全二叉树性质来求的方法。
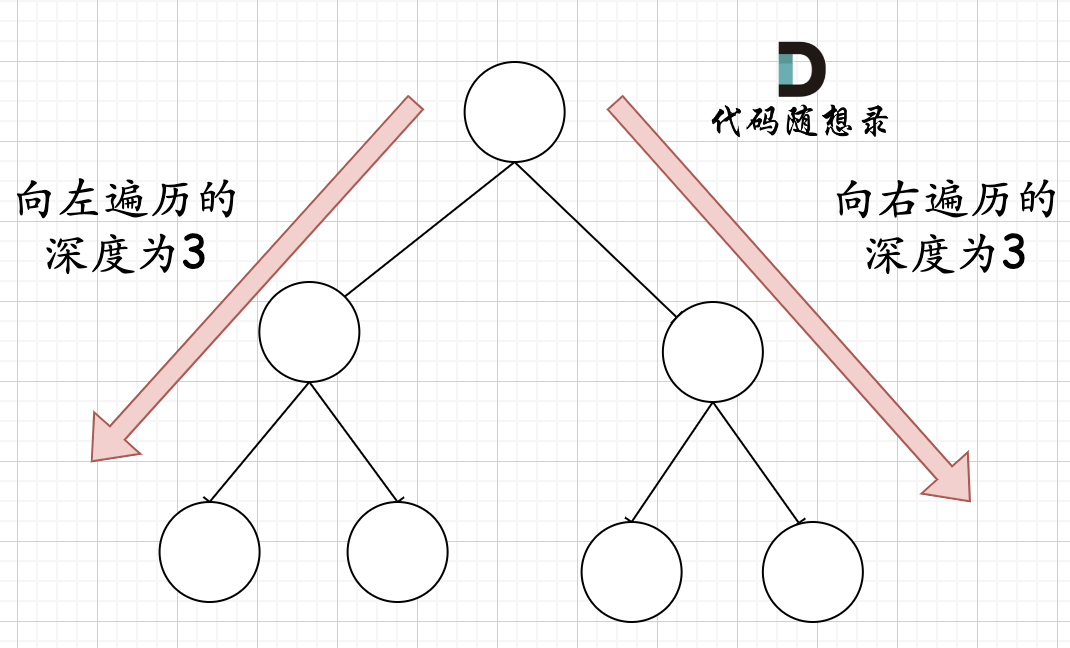
如图所示,在完全二叉树中,如果左右两边深度一样,就一定是满二叉树。
所以可以历经满二叉树的性质直接用公式来求节点个数。
class Solution {
public:
int countNodes(TreeNode* root) {
if(!root) return 0;
TreeNode* left = root->left;
TreeNode* right = root->right;
int leftDepth = 0, rightDepth = 0;
while(left) {
left = left -> left;
leftDepth++;
}
while(right) {
right = right->right;
rightDepth++;
}
if(leftDepth == rightDepth)
return (2 << leftDepth) - 1; // 这里具体怎么写要看 leftDepth, rightDepth 的初始化
return countNodes(root->left) + countNodes(root->right) + 1; // 如果不是满二叉树,就找孩子,看看孩子是不是
// 反正:不数数,所有节点都是计算得到的(公式),如果以root为根用不了公式,那就找root的孩子看看能不能用公式
}
};
如果不是满二叉树,就找孩子,看看孩子是不是。
反正:不数数,所有节点都是计算得到的(公式),如果以root为根用不了公式,那就找root的孩子看看能不能用公式。
平衡二叉树
https://leetcode.cn/problems/balanced-binary-tree/description/
class Solution {
private:
int height(TreeNode* node) {
/**
* 如果以node为root的树是平衡树,则返回这棵树的高度
* 如果不是平衡树,则不返回高度,返回-1
*/
if(node == nullptr) return 0;
int left = height(node->left);
int right = height(node->right);
if(left == -1) return -1;
if(right == -1) return -1;
return abs(left - right) > 1 ? -1 : 1 + std::max(left, right);
}
public:
bool isBalanced(TreeNode* root) {
// 首先,肯定是求左右高度的,如果左右高度超过-1,返回false就行
return height(root) == -1 ? false : true; // height函数如果返回-1,则表示不平衡,如果返回其他,表示树的高度
}
};
此题的关键就是这个 height 函数。
height函数:如果以node为root的树是平衡树,则返回这棵树的高度。如果不是平衡树,则不返回高度,返回-1。
如果用迭代法就比较复杂了。虽然理论上所有的递归都可以用迭代来实现,但是有的场景难度可能比较大。当然此题用迭代法,其实效率很低,因为没有很好的模拟回溯的过程,所以迭代法有很多重复的计算。
二叉树的所有路径(重要:回溯基本题)
https://leetcode.cn/problems/binary-tree-paths/description/
给你一个二叉树的根节点 root ,按 任意顺序 ,返回所有从根节点到叶子节点的路径。叶子节点 是指没有子节点的节点。
class Solution {
private:
std::vector<std::vector<int>> all_paths;
std::vector<int> paths;
void dfs(TreeNode* node) {
paths.push_back(node->val);
if (node->left == nullptr && node->right == nullptr) {
// 遇到叶子节点了
all_paths.push_back(paths);
return;
}
if (node->left) {
dfs(node->left);
// note: 一个递归配一个回溯
paths.pop_back();
}
if (node->right) {
dfs(node->right);
paths.pop_back();
}
} //
std::vector<std::string> vec2string() {
std::vector<std::string> res;
for(int i = 0; i < all_paths.size(); ++i) {
auto path = all_paths[i];
std::string str;
for(int j = 0; j < path.size(); ++j) {
str += std::to_string(path[j]);
if(j != path.size() - 1)
str += "->";
}
res.push_back(str);
}
return res;
}
private:
void debug_print() {
for(const auto& e : all_paths) {
for(const auto& ee : e) {
std::cout << ee << " ";
}
std::cout << std::endl;
}
}
public:
std::vector<std::string> binaryTreePaths(TreeNode* root) {
// 最后再处理成字符串吧,处理成字符串不是重点
// 先用一个 std::vector<std::vector<int>> 存
if (!root)
return {};
std::vector<std::vector<int>> all_paths;
dfs(root);
return vec2string();
}
};
这一份回溯的代码非常重要!需要记住!
特别是这一部分:
void dfs(TreeNode* node) {
paths.push_back(node->val);
if (node->left == nullptr && node->right == nullptr) {
// 遇到叶子节点了
all_paths.push_back(paths);
return;
}
if (node->left) {
dfs(node->left);
// note: 一个递归配一个回溯
paths.pop_back();
}
if (node->right) {
dfs(node->right);
paths.pop_back();
}
} //
记住!一次递归对应一次回溯(pop)
记住!一次递归对应一次回溯(pop)。
左叶子之和
https://leetcode.cn/problems/sum-of-left-leaves/description/
先自己尝试写一下吧。
class Solution {
private:
int sum = 0;
void dfs(TreeNode* node) {
if(node == nullptr) assert(false); // 通过后面的判断,不应该走到这
auto left_node = node->left;
auto right_node = node->right;
if(left_node && check_is_leaf(left_node))
sum+=left_node->val;
if(left_node) dfs(left_node);
if(right_node) dfs(right_node);
}
bool check_is_leaf(TreeNode* node) {
if(!node)
return false; // null不是叶子节点, 当然, 不会走到这
return node->left == nullptr && node->right == nullptr;
}
public:
int sumOfLeftLeaves(TreeNode* root) {
if(!root) return 0;
dfs(root);
return sum;
}
};
顺利通过,我利用 check_is_leaf 来判断这个节点是否是一个叶子结点。
给一个 Carl 版本的精简答案。
class Solution {
public:
int sumOfLeftLeaves(TreeNode* root) {
if (root == NULL) return 0;
int leftValue = 0;
if (root->left != NULL && root->left->left == NULL && root->left->right == NULL) {
leftValue = root->left->val; // 这里走进来的都是左叶子结点
}
return leftValue + sumOfLeftLeaves(root->left) + sumOfLeftLeaves(root->right);
}
};
其实就是用 leftValue + sumOfLeftLeaves(root->left) + sumOfLeftLeaves(root->right); 代替了递归的过程,其实本质是一样的。
但是我个人觉得,写一个 dfs 函数,是非常清晰的,后面很多题目,我都会去写这个 dfs 函数。
找树左下角的值
https://leetcode.cn/problems/find-bottom-left-tree-value/description/
给定一个二叉树的 根节点 root,请找出该二叉树的 最底层 最左边 节点的值。假设二叉树中至少有一个节点。
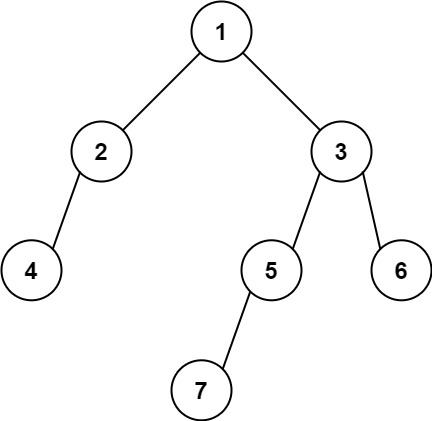
输入: [1,2,3,4,null,5,6,null,null,7]
输出: 7
先自己尝试写一下。
层序遍历法
这题用层序遍历应该是秒了。
先写一个层序遍历的版本,顺便复习一下层序遍历。
class Solution {
public:
int findBottomLeftValue(TreeNode* root) {
if(!root) assert(false); // 题目说了这种情况不可能出现
std::queue<TreeNode*> q;
std::vector<int> layer;
q.push(root);
while(!q.empty()) {
int sz = q.size();
layer.clear(); // 清空 layer 数组
for(int i = 0; i < sz; ++i) {
auto node = q.front();
q.pop();
layer.push_back(node->val);
if(node->left) q.push(node->left);
if(node->right) q.push(node->right);
}
}
return layer[0];
}
};
顺利通过。
再看看递归的方法。
递归法(有需要注意的点)
这一题递归的解法中,有非常多需要注意的地方。
- 我们需要的是,最深的那一层的,最左侧的那个节点的值。
- 调用dfs,第一个访问到的,就是最左边的! 这个就是结论,所以我们只需要按照正常dfs去访问节点就行!
- 因此,只有
cur_depth > max_depth才更新,不能是cur_depth >= max_depth!
class Solution {
private:
int max_depth = INT_MIN;
int cur_depth = 0;
int result = 0;
void dfs(TreeNode* node) {
if(cur_depth > max_depth) {
// 只能是 > 不能是 >=
max_depth = cur_depth;
result = node->val;
}
if(!node->left && !node->right) return; // 遇到叶子
if(node->left) {
cur_depth++;
dfs(node->left);
cur_depth--; // 回溯
}
if(node->right) {
cur_depth++;
dfs(node->right);
cur_depth--; // 回溯
}
}
public:
int findBottomLeftValue(TreeNode* root) {
dfs(root);
return result;
}
};
直接通过了,所以dfs这个函数是核心中的核心!
路径总和
https://leetcode.cn/problems/path-sum/description/
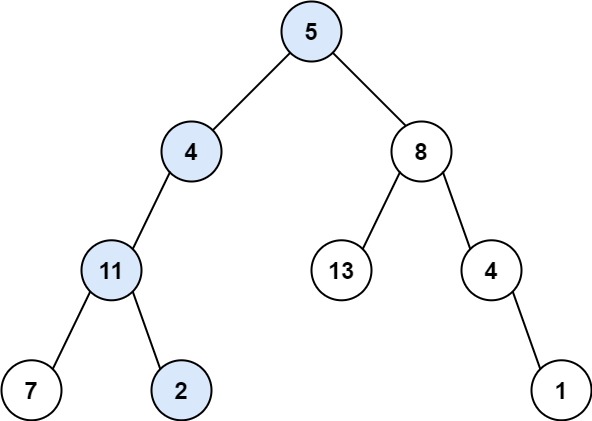
输入:root = [5,4,8,11,null,13,4,7,2,null,null,null,1], targetSum = 22
输出:true
解释:等于目标和的根节点到叶节点路径如上图所示。
回溯所有路径就行了。
class Solution {
private:
std::vector<int> path;
bool flag = false;
void dfs(TreeNode* root, int targetSum) {
if(flag == true) return; // 剪枝
path.push_back(root->val);
if(!root->left && !root->right) {
int sum = std::accumulate(path.begin(), path.end(), 0);
if(sum == targetSum) flag = true; // 如果符合,则调整为true
return;
}
if(root->left) {
dfs(root->left, targetSum);
path.pop_back(); // 回溯
}
if(root->right) {
dfs(root->right, targetSum);
path.pop_back(); // 回溯
}
}
public:
bool hasPathSum(TreeNode* root, int targetSum) {
if(!root) return false; // 题目说明了这种情况
dfs(root, targetSum);
return flag;
}
};
顺利通过,这种回溯路径的题目是很经典的,后面很多时候都会遇到类似的。
在代码里面,我设置了,一遇到 flag == true 直接剪枝返回即可。
这里是相似的一道题 113. 路径总和 II
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
和上一题没有任何区别,但是,这题不能剪枝了,因为题目要找所有符合条件的路径。
class Solution {
private:
std::vector<std::vector<int>> all_paths;
std::vector<int> path;
void dfs(TreeNode* root, int targetSum) {
path.push_back(root->val);
if(!root->left && !root->right) {
int sum = std::accumulate(path.begin(), path.end(), 0);
if(sum == targetSum) all_paths.push_back(path); // 这里稍微调整即可
return;
}
if(root->left) {
dfs(root->left, targetSum);
path.pop_back(); // 回溯
}
if(root->right) {
dfs(root->right, targetSum);
path.pop_back(); // 回溯
}
}
public:
vector<vector<int>> pathSum(TreeNode* root, int targetSum) {
if(!root) return {}; // 题目说明了这种情况
dfs(root, targetSum);
return all_paths;
}
};
从中序与后序遍历序列构造二叉树(重要题型)
https://leetcode.cn/problems/construct-binary-tree-from-inorder-and-postorder-traversal/description/
思路和分析
首先给两个序列。
inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
后序最后一个数是3,说明3就是树的根!因为3肯定是最后访问。
然后在中序里面,3的左边是9,3的右边是15,20,7。 表明9就是3的左子树,15,20,7就是3的右子树。
所以代码的步骤可以是这样的:
- 第一步:如果数组大小为零的话,说明是空节点了。
- 第二步:如果不为空,那么取后序数组最后一个元素作为节点元素。
- 第三步:找到后序数组最后一个元素在中序数组的位置,作为切割点
- 第四步:切割中序数组,切成中序左数组和中序右数组 (顺序别搞反了,一定是先切中序数组)
- 第五步:切割后序数组,切成后序左数组和后序右数组
- 第六步:递归处理左区间和右区间
不难写出下面这个代码结构。
TreeNode* traveral(std::vector<int>& inorder, std::vector<int>& postorder) {
// 第一步
if (postorder.size() == 0)
return nullptr;
// 第二步
int rootValue = postorder[postorder.size() - 1];
TreeNode* root = new TreeNode(rootValue);
// 叶子节点
if(postorder.size() == 1) return root;
// 第三步:寻找切割点
int delimiterIndex;
for(delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
if(inorder[delimiterIndex] == rootValue) break;
}
// 第四步:切割中序数组,得到中序左数组和中序右数组
// 第五步:切割后序数组,得到后序左数组和后序右数组
root->left = traveral(/*中序左数组*/, /*中序右数组*/);
root->right = traveral(/*后序左数组*/, /*后序右数组*/);
}
中序数组相对比较好切,找到切割点(后序数组的最后一个元素)在中序数组的位置,然后切割。
中序切割很好理解,比如上面那个例子。
inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
第一次是以3为切割点,所以中序左数组就是 [9], 中序右数组就是 [15, 20, 7]。
// 找到中序遍历的切割点
int delimiterIndex;
for (delimiterIndex = 0; delimiterIndex < inorder.size(); delimiterIndex++) {
if (inorder[delimiterIndex] == rootValue) break;
}
// 左闭右开区间:[0, delimiterIndex)
vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
// [delimiterIndex + 1, end)
vector<int> rightInorder(inorder.begin() + delimiterIndex + 1, inorder.end() );
后序切割其实也不难。
inorder = [9,3,15,20,7], postorder = [9,15,7,20,3]
中序左数组就是 [9], 中序右数组就是 [15, 20, 7]
首先第一步,先把3去掉,3已经用过了。
此时 postorder=[9,15,7,20]
后序左数组,就是从数组开头,数leftInorder.size()个数, 也就是数一个。
后序右数组,就是从第leftInorder.size()+1个开始数,到结尾。
可以写出下面这份代码。
// postorder 舍弃末尾元素,因为这个元素就是中间节点,已经用过了
postorder.resize(postorder.size() - 1);
// 左闭右开,注意这里使用了左中序数组大小作为切割点:[0, leftInorder.size)
vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());
// [leftInorder.size(), end)
vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());
完整实现代码
class Solution {
private:
TreeNode* traveral(std::vector<int>& inorder, std::vector<int>& postorder) {
if(postorder.size() == 0) return nullptr;
int rootValue = postorder[postorder.size()-1]; // 当前节点就是后序最后一个节点
TreeNode* root = new TreeNode(rootValue); // 构建新节点
// 叶子结点
if(postorder.size() == 1) return root; // 此时的root已经是叶子结点了
// 找到中序的切割点
int delimiterIndex = -1;
for(delimiterIndex = 0; delimiterIndex < inorder.size(); ++delimiterIndex) {
if(inorder[delimiterIndex] == rootValue) break;
}
// 切割中序数组
std::vector<int> leftInorder(inorder.begin(), inorder.begin() + delimiterIndex);
std::vector<int> rightInorder(inorder.begin()+delimiterIndex+1, inorder.end());
assert(leftInorder.size() + rightInorder.size() == postorder.size()-1);
// 切割后序数组
postorder.pop_back(); // 去掉最后一个元素(rootValu)
std::vector<int> leftPostorder(postorder.begin(), postorder.begin()+leftInorder.size());
std::vector<int> rightPostorder(postorder.begin()+leftInorder.size(), postorder.end());
root->left = traveral(leftInorder, leftPostorder);
root->right = traveral(rightInorder, rightPostorder);
return root;
}
public:
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {
if(inorder.size() == 0 || postorder.size() == 0) return nullptr;
return traveral(inorder, postorder);
}
};
可以优化的地方
当然,像上面那样肯定是最好理解的,但是重新构建新 vector 肯定是效率不高的,所以其实就永远来的数组,然后用下标来表示新数组,是更好的。
这道题的主要是要学会这个思路。关于下标/迭代器区间的处理,我个人是比较熟练的,因此我觉得,只要在草稿纸上分析过,下标注意一下,应该是不会有问题的。
从前序与中序遍历序列构造二叉树(重要题型)
https://leetcode.cn/problems/construct-binary-tree-from-preorder-and-inorder-traversal/description/
这道题的思路和上面那个题是一样的,这里就写下这道题,当作上道题的巩固。
然后这道题尝试用指针的方法去做,这样更好。
我用了迭代器。
class Solution {
private:
using itType = std::vector<int>::iterator;
TreeNode* traveral(const std::vector<int>& preorder, const std::vector<int>& inorder,
itType leftPreorderIndex, itType rightPreorderIndex, itType leftInorderIndex, itType rightInorderIndex) {
if(rightPreorderIndex - leftPreorderIndex == 0) return nullptr; // 没有节点
int rootValue = *leftPreorderIndex; // 第一个数组就是要找的
TreeNode* root = new TreeNode(rootValue); // 此时的根
if(rightPreorderIndex - leftPreorderIndex == 1) return root; // 此时的root是叶子节点
itType delimiterIndex;
for(delimiterIndex = leftInorderIndex; delimiterIndex != rightInorderIndex; delimiterIndex++)
if(*delimiterIndex == rootValue) break;
// 此时 delimiterIndex 指向中序的切割点
// 切割中序数组
itType left_leftInorderIndex = leftInorderIndex;
itType right_leftInorderIndex = delimiterIndex;
itType left_rightInorderIndex = delimiterIndex + 1;
itType right_rightInorderIndex = rightInorderIndex;
// 切割前序数组
leftPreorderIndex++; // pop_front 一下
itType left_leftPreorderIndex = leftPreorderIndex;
itType right_leftPreorderIndex = leftPreorderIndex + (right_leftInorderIndex - left_leftInorderIndex);
itType left_rightPreorderIndex = leftPreorderIndex + (right_leftInorderIndex - left_leftInorderIndex);
itType right_rightPreorderIndex = rightPreorderIndex;
// 递归
root->left = traveral(preorder, inorder, left_leftPreorderIndex, right_leftPreorderIndex, left_leftInorderIndex, right_leftInorderIndex);
root->right = traveral(preorder, inorder, left_rightPreorderIndex, right_rightPreorderIndex, left_rightInorderIndex, right_rightInorderIndex);
return root;
} //
public:
TreeNode* buildTree(std::vector<int>& preorder, std::vector<int>& inorder) {
if (preorder.size() == 0 || inorder.size() == 0)
return nullptr;
return traveral(preorder, inorder, preorder.begin(), preorder.end(), inorder.begin(), inorder.end());
}
};
顺利通过。
这道两道题是需要复习的!
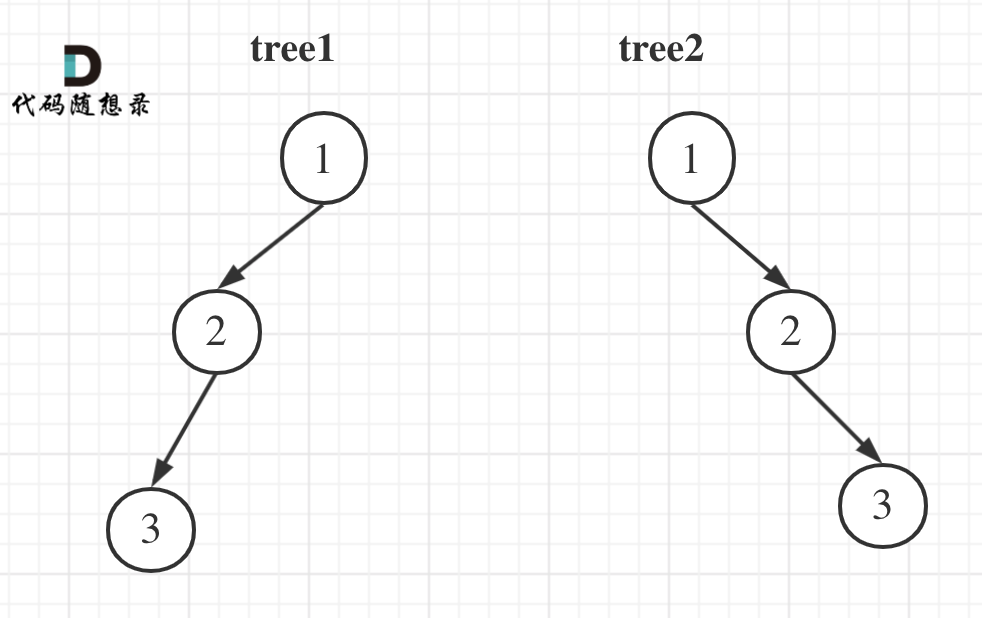
前序+后序能确定一棵二叉树吗?
前序和后序不能唯一确定一棵二叉树!,因为没有中序遍历无法确定左右部分,也就是无法分割。
举一个例子:
最大二叉树
https://leetcode.cn/problems/maximum-binary-tree/description/
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为
nums中的最大值。 - 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
这题不是和105, 106那两题完全一样的方法去构造不就可以了。直接写代码。
class Solution {
private:
using iterator = std::vector<int>::iterator;
TreeNode* build(const std::vector<int>& nums, iterator left, iterator right) {
if(right - left == 0) return nullptr;
iterator maxValueIndex = std::max_element(left, right); // 找到最大值的索引
TreeNode* root = new TreeNode(*maxValueIndex); // 构建节点
// 左子数组
iterator leftLeft = left;
iterator rightLeft = maxValueIndex;
// 右子数组
iterator leftRight = maxValueIndex + 1;
iterator rightRight = right;
root->left = build(nums, leftLeft, rightLeft); // 递归
root->right = build(nums, leftRight, rightRight); // 递归
return root;
}
public:
TreeNode* constructMaximumBinaryTree(std::vector<int>& nums) {
if(nums.size() == 0) return nullptr;
return build(nums, nums.begin(), nums.end());
}
};
顺利通过。
合并二叉树
https://leetcode.cn/problems/merge-two-binary-trees/description/
先自己尝试写代码。
class Solution {
public:
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
if(!root1 && !root2) return nullptr;
else if(!root1 && root2) return root2;
else if(root1 && !root2) return root1;
else if(root1 && root2) {
TreeNode* new_node = new TreeNode(root1->val+root2->val);
new_node->left = mergeTrees(root1->left, root2->left);
new_node->right = mergeTrees(root1->right, root2->right);
return new_node;
}
assert(false);
return nullptr;
}
};
顺利通过啊,很简单,分情况就行了。如果一边为空,则返回另一边就行了。
开始找到大一时候的感觉了。
二叉搜索树中的搜索
https://leetcode.cn/problems/search-in-a-binary-search-tree/description/
这题就是搜索树的查找,很简单。当然这份代码很重要,后面很多时候都要用,要写好一点。
class Solution {
public:
TreeNode* searchBST(TreeNode* root, int val) {
if(!root) return nullptr;
TreeNode* cur = root;
while(cur) {
if(cur->val == val) return cur;
else if(cur->val > val) cur = cur->left;
else if(cur->val < val) cur = cur->right;
}
return nullptr;
}
};
进入搜索树的题目范畴了,就不要轻易递归了,迭代肯定是最快的,毕竟后面红黑树,AVL都是基于此!(个人总结)
验证二叉搜索树
https://leetcode.cn/problems/validate-binary-search-tree/description/
中序遍历下,输出的二叉搜索树节点的数值是有序序列!
所以这题就好好复习下中序遍历的各种写法。
递归法:
class Solution {
private:
std::vector<int> vec;
void dfs(TreeNode* root) {
if(!root) return;
dfs(root->left);
vec.push_back(root->val);
dfs(root->right);
}
public:
bool isValidBST(TreeNode* root) {
if(!root) return true;
dfs(root);
return std::is_sorted(vec.begin(), vec.end()) && std::set<int>(vec.begin(), vec.end()).size() == vec.size();
}
};
return std::is_sorted(vec.begin(), vec.end()) && std::set<int>(vec.begin(), vec.end()).size() == vec.size();
我用这个方法来判断是否有重复值,这样效率一般。不过这不是本题的重点。
利用stack来进行深度优先遍历。
class Solution {
private:
std::vector<int> vec;
void dfs_by_stack(TreeNode* root) {
std::stack<TreeNode*> st;
st.push(root);
while(!st.empty()) {
auto node = st.top();
if(node) {
st.pop(); // 先弹出这个节点,避免重复操作
// 中序需要 左 中 右
// 因此按照 右 中 左 的顺序处理
if(node->right) st.push(node->right);
st.push(node);
st.push(nullptr);
if(node->left) st.push(node->left);
} else if(node == nullptr) {
// 遇到null了
st.pop();
node = st.top();
st.pop();
vec.push_back(node->val); // 处理这个节点,这个节点被null标记,可以处理
}
}
}
public:
bool isValidBST(TreeNode* root) {
if(!root) return true;
dfs_by_stack(root);
return std::is_sorted(vec.begin(), vec.end()) && std::set<int>(vec.begin(), vec.end()).size() == vec.size();
}
};
二叉搜索树的最小绝对差
https://leetcode.cn/problems/minimum-absolute-difference-in-bst/
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
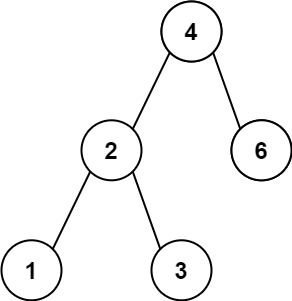
输入:root = [4,2,6,1,3] 输出:1
我的思路是,遍历不就好了?那就是求有序数组的最小差值。
送分题。
直接写代码:
class Solution {
private:
std::vector<int> vec;
void dfs(TreeNode* root) {
if(!root) return;
dfs(root->left);
vec.push_back(root->val);
dfs(root->right);
}
public:
int getMinimumDifference(TreeNode* root) {
if (!root) assert(false); // 题目说了至少两个节点
dfs(root);
int diff = INT_MAX;
for(int i = 1; i < vec.size(); ++i) {
int cur_diff = vec[i] - vec[i-1];
diff = std::min(cur_diff, diff);
}
return diff;
}
};
顺利通过。
当然,现在是遍历两遍。也可以优化成遍历一遍的,在中序遍历的时候,就把最小差值记下来就行了。
二叉搜索树中的众数
https://leetcode.cn/problems/find-mode-in-binary-search-tree/
给你一个含重复值的二叉搜索树(BST)的根节点 root ,找出并返回 BST 中的所有 众数(即,出现频率最高的元素)。
如果树中有不止一个众数,可以按 任意顺序 返回。
刚才上面那题说了,可以只遍历一次的,利用搜索树的性质。
所以这里用两个指针记录一下就行了。
class Solution {
private:
TreeNode* prev = nullptr; // 记录上一个遍历上一个节点的指针
int count = 0; // 记录当前遍历到的节点的频率
int maxCount = 0; // 记录最大频率
std::vector<int> res;
void dfs(TreeNode* root) {
if(!root) return;
dfs(root->left);
/* ------------- 逻辑处理 ------------- */
if(prev == nullptr)
// 算法开头,刚开始遍历树的第一个节点
count = 1;
else if(prev && prev->val == root->val)
count++; // 当前节点和上个节点值相同
else if(prev && prev->val != root->val)
count = 1; // 刷新一下
if(count == maxCount)
// 按照题目要求:如果树中有不止一个众数,可以按 任意顺序 返回。
res.push_back(root->val);
if(count > maxCount) {
maxCount = count;
res.clear(); // 刷新结果
res.push_back(root->val);
}
prev = root; // 迭代
/* ------------- 逻辑处理 ------------- */
dfs(root->right);
}
public:
vector<int> findMode(TreeNode* root) {
dfs(root);
return res;
}
};
顺利通过。
其实很简单,反正就是在两个 dfs 调用之间来操作,就是中序。
二叉树的最近公共祖先(需要复习)
https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-tree/
这题其实有点难,一开始老想不明白。
这次看了Carl的视频讲解是看明白了。
比如一棵树:
8
3 12
1 6 11 13
遍历节点,然后写一个函数,判断p,q节点是不是在子树中
比如p,q是1和6,那么回溯到3的时候,两边都是非空的,这样就把3继续返回。
到8的时候,左边不为空,右边为空。所以此时继续返回下面的3。这就得到最后的结果了。因此我先尝试自己写写代码。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(!root) return nullptr;
if(root == p || root == q) return root;
if(root->left == p && root->right == q) return root;
if(root->right == p && root->left == q) return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if(left && right) return root; // 这个是公共祖先
if(!left && right) return right;
if(left && !right) return left;
return nullptr;
}
};
搞清楚思路后直接通过了。
二叉搜索树的最近公共祖先
https://leetcode.cn/problems/lowest-common-ancestor-of-a-binary-search-tree/description/
这题肯定是要好好利用搜索树的性质的。
我自己先想想,很明显是可以用二叉搜索树二分查找那个性质的。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(!root) return nullptr;
if(root ==p || root == q) return root;
if(root->val > p->val && root->val < q->val) return root;
else if(root->val < p->val && root->val > q->val) return root;
else if(root->val > p->val && root->val > q->val) return lowestCommonAncestor(root->left, p, q);
else if(root->val < p->val && root->val < q->val) return lowestCommonAncestor(root->right, p, q);
return nullptr;
}
};
比大小就行,顺利通过。
当然,Carl的做法更精简一点。
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root->val > p->val && root->val > q->val) {
return lowestCommonAncestor(root->left, p, q);
} else if (root->val < p->val && root->val < q->val) {
return lowestCommonAncestor(root->right, p, q);
} else return root;
}
};
因为除了两个递归的情况,其他情况都是返回root的。
二叉搜索树中的插入操作
给定二叉搜索树(BST)的根节点 root 和要插入树中的值 value ,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。
注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果。
https://leetcode.cn/problems/insert-into-a-binary-search-tree/description/
这题真的是之前手搓红黑树时必会的。
先自己写。
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(!root)
return new TreeNode(val);
// 肯定是要插入到叶子上的
TreeNode* cur = root;
TreeNode* pre = nullptr;
while(cur) {
pre = cur; // 记录 pre
if(cur->val > val) cur = cur->left;
else if(cur->val < val) cur = cur->right;
else if(cur->val == val) assert(false);
}
// 此时 cur 是一个叶子节点
if(pre->val > val) pre->left = new TreeNode(val);
if(pre->val < val) pre->right = new TreeNode(val);
return root;
}
};
顺利通过。
删除二叉搜索树中的节点(难)
https://leetcode.cn/problems/delete-node-in-a-bst/description/
情况比较复杂,分清楚情况就可以了。
- 第一种情况:没找到删除的节点,遍历到空节点直接返回了找到删除的节点
- 第二种情况:左右孩子都为空(叶子节点),直接删除节点, 返回NULL为根节点
- 第三种情况:删除节点的左孩子为空,右孩子不为空,删除节点,右孩子补位,返回右孩子为根节点
- 第四种情况:删除节点的右孩子为空,左孩子不为空,删除节点,左孩子补位,返回左孩子为根节点
- 第五种情况:左右孩子节点都不为空,则将删除节点的左子树头结点(左孩子)放到删除节点的右子树的最左面节点的左孩子上,返回删除节点右孩子为新的根节点。
第五种比较难理解:如动画所示即可。
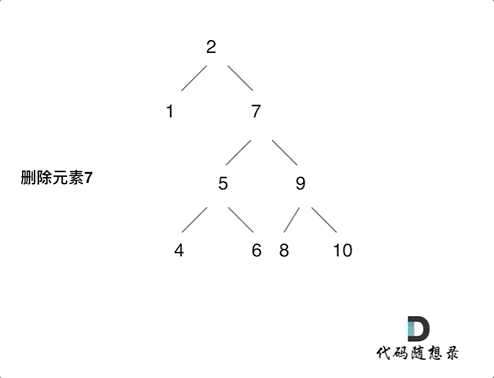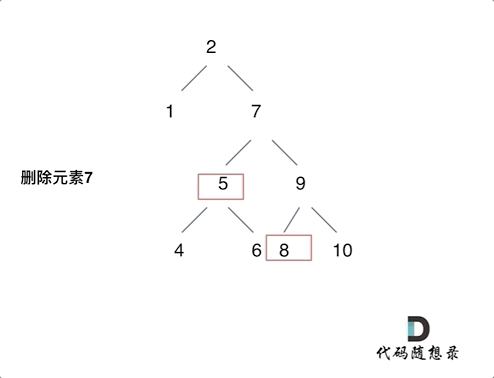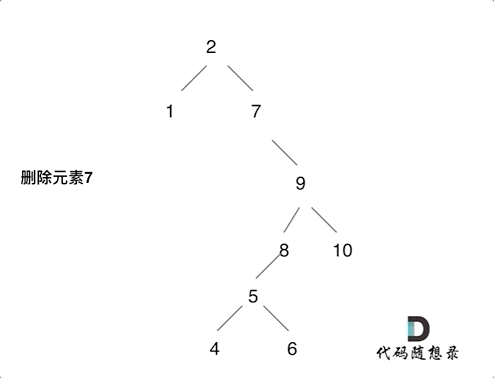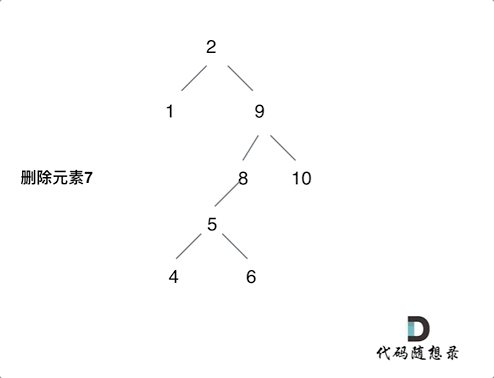
每一种情况都自己画画图就都能理解了。
无论是迭代还是递归,都是分清楚这5种情况即可。
照着这个思路尝试写下代码。
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
if(!root) return nullptr;
// 找要删除的节点
TreeNode* cur = root;
TreeNode* parent = nullptr;
while(cur) {
if(cur->val > key) {
parent = cur;
cur = cur->left;
}
else if(cur->val < key) {
parent = cur;
cur = cur->right;
}
else if(cur->val == key) {
// 找到了需要删除的节点
// 2. 这个节点是叶子
if(!cur->left && !cur->right) {
if(parent == nullptr) {
// 根是要删除的
delete cur;
return nullptr;
}
if(cur == parent->left) parent->left = nullptr;
else if(cur == parent->right) parent->right = nullptr;
}
// 3. 左孩子为空
else if(!cur->left && cur->right) {
if(parent == nullptr) {
// 根是要删除的
auto tmp = cur->right;
delete cur;
return tmp;
}
if(cur == parent->left)
parent->left = cur->right;
else
parent->right = cur->right;
}
// 4. 右孩子为空
else if(cur->left && !cur->right) {
if(parent == nullptr) {
// 根是要删除的
auto tmp = cur->left;
delete cur;
return tmp;
}
if(cur == parent->left)
parent->left = cur->left;
else
parent->right = cur->left;
}
// 5. 左右孩子都不为空
else {
// 把cur左子树的所有东西,放到cur右子树的最左边
// 5.1. 先找到cur右子树的最左边
TreeNode* ccur = cur->right;
TreeNode* ppre = nullptr;
while(ccur) {
ppre = ccur;
ccur = ccur->left;
}
// 此时 ppre 就是 cur 右子树的最左节点
assert(ppre->left == nullptr);
ppre->left = cur->left;
if(parent == nullptr) {
// 根是要删除的
auto tmp = cur->right;
delete cur;
return tmp;
}
if(cur == parent->left)
parent->left = cur->right;
else
parent->right = cur->right;
}
delete cur;
return root;
}
}
return root; // 1. 没有找到这个节点
}
};
按照思路写确实通过了,不过这题确实不简单。
普通二叉树的删除
普通二叉树的删除方式(没有使用搜索树的特性,遍历整棵树),用交换值的操作来删除目标节点。
代码中目标节点(要删除的节点)被操作了两次:
- 第一次是和目标节点的右子树最左面节点交换。
- 第二次直接被NULL覆盖了。
思路有点绕,其实就是换走,然后被覆盖就行。画个图就能理解,这里不详细说了。
修剪二叉树(需要复习)
递归法
给定一个二叉搜索树,同时给定最小边界L 和最大边界 R。通过修剪二叉搜索树,使得所有节点的值在[L, R]中 (R>=L) 。你可能需要改变树的根节点,所以结果应当返回修剪好的二叉搜索树的新的根节点。
意思就是只留下区间里面的节点。
https://leetcode.cn/problems/trim-a-binary-search-tree/description/
这题的思路看起来有点难,但是听了Carl的讲解之后,就能理解了。
还是要对递归要有更深的理解才可以。
其实这里是分情况,也是遍历:
- 如果不符合条件,一边的子树是有可能符合的(搜索树的性质)
- 如果符合条件,则左右分别遍历
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int low, int high) {
if(!root) return nullptr;
if(root->val < low) return trimBST(root->right, low, high); // 右孩子是有概率符合条件的
if(root->val > high) return trimBST(root->left, low, high);
root->left = trimBST(root->left, low, high);
root->right = trimBST(root->right, low, high);
return root;
}
};
直接通过了。
迭代法(需要理解这种思路)
- 修剪后的树的root一定是在[L, R]之间的,所以如果root不在范围内,先把root调整到范围内
- 然后在root的左边,可能存在 < L 的节点,删除这些节点
- 在root的右边,可能存在 > R 的节点,删除这些节点
class Solution {
public:
TreeNode* trimBST(TreeNode* root, int L, int R) {
if (!root) return nullptr;
// 处理头结点,让root移动到[L, R] 范围内,注意是左闭右闭
while (root != nullptr && (root->val < L || root->val > R)) {
if (root->val < L) root = root->right; // 小于L往右走
else root = root->left; // 大于R往左走
}
TreeNode *cur = root;
// 此时root已经在[L, R] 范围内,处理左孩子元素小于L的情况
while (cur != nullptr) {
while (cur->left && cur->left->val < L) {
cur->left = cur->left->right;
}
cur = cur->left;
}
cur = root;
// 此时root已经在[L, R] 范围内,处理右孩子大于R的情况
while (cur != nullptr) {
while (cur->right && cur->right->val > R) {
cur->right = cur->right->left;
}
cur = cur->right;
}
return root;
}
};
将有序数组转换为二叉搜索树(可以联想到:AVL的旋转)
https://leetcode.cn/problems/convert-sorted-array-to-binary-search-tree/description/
递归法(简单)
二分的思想其实就是,一个有序数组,让中间的那个来当根。数组分成两半来递归。
class Solution {
private:
using iter = std::vector<int>::iterator;
TreeNode* buildBST(const std::vector<int>& vec, iter begin, iter end) {
if(begin >= end) return nullptr;
iter mid = begin + ((end - begin) / 2);
TreeNode* root = new TreeNode((*mid));
root->left = buildBST(vec, begin, mid); // 构造左子树
root->right = buildBST(vec, mid + 1, end); // 构造右子树
return root;
}
public:
TreeNode* sortedArrayToBST(vector<int>& nums) {
return buildBST(nums, nums.begin(), nums.end());
}
};
递归法很容易理解。
迭代法(Carl介绍的迭代法模拟递归)
有点复杂,先略过了。
红黑树插入时旋转保持平衡特性
要维护平衡因子,这里不弄了。后面我会复习手撕avl和红黑树的。
把二叉搜索树转换为累加树(反中序遍历)
https://leetcode.cn/problems/convert-bst-to-greater-tree/
https://leetcode-cn.com/problems/binary-search-tree-to-greater-sum-tree/
两个题是一样的。
给出二叉 搜索 树的根节点,该树的节点值各不相同,请你将其转换为累加树(Greater Sum Tree),使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
我想到的思路比较捞:
我先中序遍历,遍历结果存的是节点。然后reverse一下。然后求前缀和。
中序遍历是 O(n), reverse是 O(n), 求前缀和也是 O(n)。
所以最后的效率也是 O(n)。
虽然思路一般,但是效率好像还行,我先用这种方法做。
class Solution {
public:
std::vector<TreeNode*> inOrder;
void dfs(TreeNode* root) {
if(!root)return;
dfs(root->left);
inOrder.push_back(root);
dfs(root->right);
}
TreeNode* convertBST(TreeNode* root) {
dfs(root); // 1. 中序遍历
std::reverse(inOrder.begin(), inOrder.end()); // 2. 求倒序
// 3. 求前缀和
for(int i = 1; i < inOrder.size(); ++i)
inOrder[i]->val = inOrder[i]->val + inOrder[i-1]->val;
return root;
}
};
顺利通过。
Carl的思路:
因为数组大家都知道怎么遍历啊,从后向前,挨个累加就完事了,这换成了二叉搜索树,看起来就别扭了一些是不是。
那么知道如何遍历这个二叉树,也就迎刃而解了,从树中可以看出累加的顺序是右中左,所以我们需要反中序遍历这个二叉树,然后顺序累加就可以了。
class Solution {
public:
int pre = 0;
void dfs(TreeNode* root) {
if(!root)return;
dfs(root->right); // 反中序遍历
root->val += pre;
pre = root->val;
dfs(root->left);
}
TreeNode* convertBST(TreeNode* root) {
dfs(root);
return root;
}
};
按照思路走,也顺利通过了。
二叉树到这里就完结了。二叉树和前面的内容一定要复习!
复习的文档: binary_tree_review.md