什么是IO?IO的本质?|如何让IO变得高效?何为高效?|异步IO|多路转接|reactor模式

什么是IO,IO的本质是什么?
要搞清楚这个问题,我们首先要了解5种最重要的IO模型!
阻塞IO
非阻塞IO
信号驱动IO
多路转接
异步IO
五种IO模型和一些基本概念
阻塞IO
在内核将数据准备好之前,系统调用会一直等待.所有的套接字,默认都是阻塞方式。
简单来说,我要向一个文件描述符做读取这个操作,这个文件描述符里面没有数据,我就一直阻塞等待!
非阻塞IO
如果内核还未将数据准备好,系统调用仍然会直接返回,并且返回EWOULDBLOCK错误码。
简单来说,我向一个文件描述符做读取,如果有数据,则成功读取返回,如果没有数据,也返回,但带上EWOULDBLOCK错误码。
使用这种方式的话,我们做读取,就必须每隔一段时间去看看,这个文件描述符到底来数据没有,这个其实就是我们常说的非阻塞轮询检测方案!
轮询一般比较吃CPU资源,因此纯非阻塞IO一般只在特定的场景下使用。
信号驱动IO
内核将数据准备好的时候,使用SIGIO信号通知应用程序进行IO操作。
多路转接
多路转接I/O(Multiplexing I/O)是一种用于管理多个I/O操作的技术。它允许单个线程或进程同时监视和处理多个I/O事件,而无需为每个I/O操作创建单独的线程或进程。
而多路转接I/O利用了操作系统提供的一些机制,如select、poll、epoll(Linux)或kqueue(FreeBSD、MacOSX),来同时监视多个I/O事件的状态。
这些机制允许程序将多个I/O事件(如套接字的读写事件)注册到一个事件集合中。然后,程序可以通过调用特定的系统调用,如select或epoll_wait,来阻塞等待其中任何一个I/O事件就绪。
一旦有就绪的I/O事件发生,程序就可以通过事件集合得知是哪些I/O操作已经就绪,并对它们进行处理。这种方式避免了阻塞等待单个I/O操作完成的情况,提高了并发处理能力和效率。
多路转接I/O适用于需要同时处理多个I/O事件的情况,特别适用于网络服务器、消息队列、实时流处理等场景。通过使用多路转接I/O,可以减少线程或进程的创建和切换开销,提高系统的性能和资源利用率。
其实通俗来说,就是一个进程,我可以同时监听多个文件描述符,哪一个文件描述符的特定事件就绪了,就提醒上层。
异步IO
异步I/O的关键概念是回调(Callback)和事件循环(Event Loop)。在异步I/O模型中,当程序发起一个I/O操作时,它会注册一个回调函数,并将控制权返回给调用者。当I/O操作完成时,系统会通知程序,并在适当的时机调用事先注册的回调函数。程序可以在回调函数中处理已完成的I/O操作的结果。
异步I/O的优势在于可以在等待I/O操作完成的同时继续执行其他任务,提高了并发处理能力和系统的响应性能。由于无需为每个I/O操作创建额外的线程或进程,异步I/O模型对系统资源的消耗也较低。
比如说Reactor就是一种异步IO的应用。
同步通信 vs 异步通信
同步和异步关注的是消息通信机制
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了;换句话说,就是由调用者主动等待这个调用的结果。
异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果,而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。
这个和多线程的同步互斥,不是同一个概念,不要大家不要搞混了。
阻塞队列
阻塞队列其实就是一种同步阻塞IO的应用方式。
当然,和这个类似还有环形队列,当然其实本质都一样,因为他们都会阻塞!!
什么是低效的IO?什么是高效的IO?
我们通过上面的描述,已经可以总结出一个非常非常非常重要的结论:
IO = 等 + 拷贝数据(把数据从文件描述符里拷贝出来或拷贝到文件描述符里去)
这个结论非常的重要!
那么通过这个结论,我们如何提高IO的效率呢?或者说,什么是高效的IO?什么低效呢?
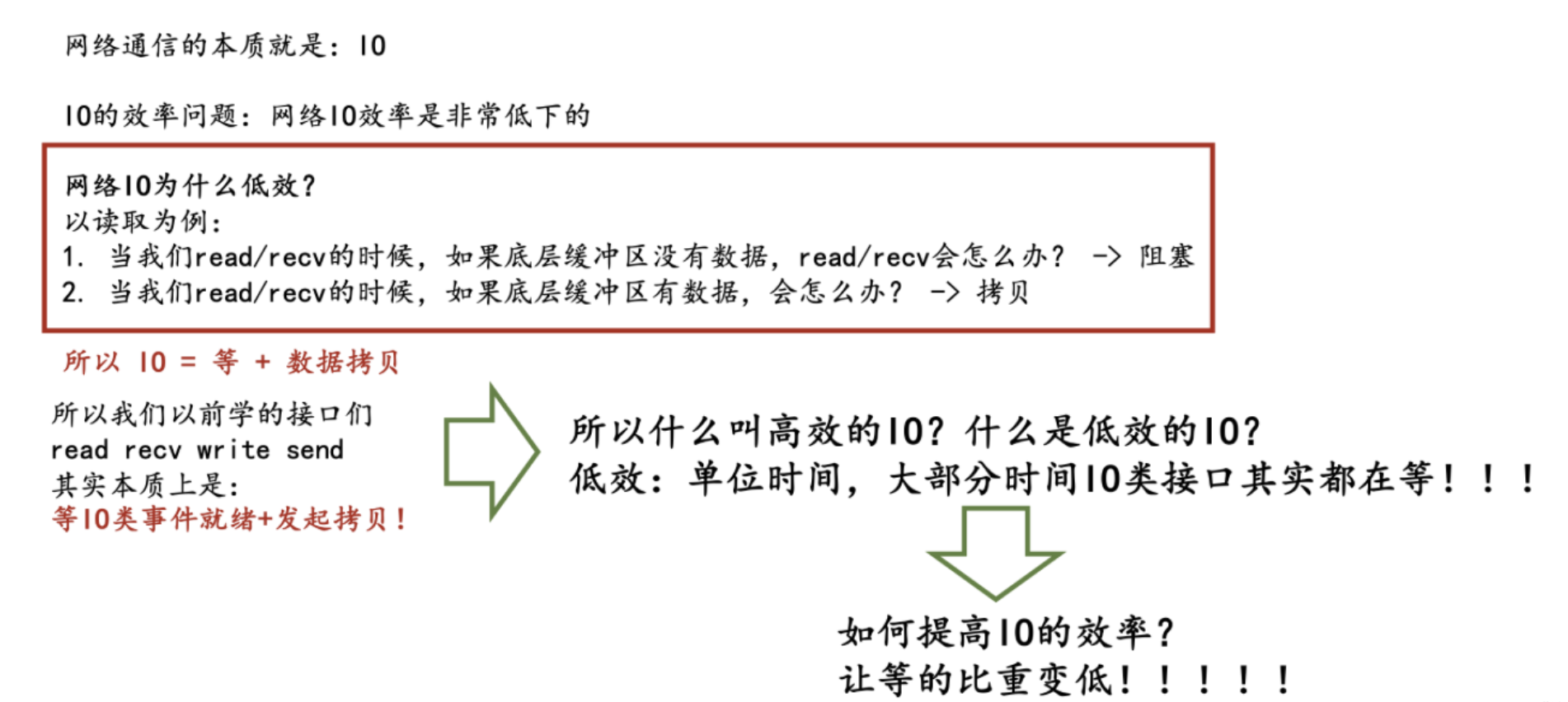
答案:让等的比重降低!!!!!
如何让等的比重降低?最有效的方法其实就是多路转接了。
多路转接
其中,值得我们学习的,就是多路转接的select,poll和epoll。
关于这三种多路转接的方式,已经做成Github的项目。
为什么需要这些IO模型?
但是上面提到的IO模型,怎么把他们用起来呢?我们为什么要追求极致的效率?为什么我们需要我们的IO很快?
其实,本地上,我们肯定看不到IO模型的优势,但是在网络场景下,高效的IO模型就非常重要了!
网络是会丢包的!是会延时的!是会出错的!不然为什么会有TCP这些协议呢?
针对于上面这些IO模型,其实就会衍生出两种主要的网络服务模型,Apache和Nginx。